
The Odyssey of getting my data into Amazon Glacier
For years, I've been accumulating an archive of files at home on an external drive connected to a Mac mini. These are files that I do not expect to need in the future, but at the same time wouldn’t really be happy about losing—for example, snapshots of filesystems of computers I've retired, some source media, etc. All in all, the drive contains some 300 GB of data.
Since hard drives are prone to dying, especially in a hot climate like southern Spain, I've been using the excellent Arq from Haystack Software to keep an offsite copy of these files stored in Amazon Glacier—costing me about $3 per month.
Then a few weeks ago, I got to thinking that I'd probably be fine just storing these files exclusively in Amazon Glacier, and doing away with the local hard drive altogether. The risk I'd be exposed to is the probability that Glacier loses a file, multiplied by the probability that I'd actually need that particular file. That should be quite low.
So with that in mind, I formulated a plan to make it happen: Using my other server—a fat-piped Mac mini hosted with one of the Mac mini colocators—I would use Arq to restore my 300 GB of data there, and then re-upload it all using Transmit to an Amazon S3 bucket, configured with a lifecycle rule to immediately transfer it all into Glacier.
(You might be wondering why I didn’t just leave Arq’s data in place, and ditch the source drive. Two reasons. First, as far as I can tell, Arq is tool to backup, not move, data; i.e. it seems to prefer the local data to stick around. Second, Arq encrypts data before uploading to Glacier, and so I’d forever be dependent on Arq to restore it.
You might also be wondering why I didn’t just upload the local data to Amazon S3. That’d be because I live in southern Spain, where we have awful ADSL, and didn’t want to spend another seven months waiting for the upload to happen.)
So that was the plan. Beautiful. Except that, as we all know, plans never work out as planned.
Restoring from Glacier
The first step was getting Arq’s data restored to my internet-hosted Mac mini. So I fired up Arq on that machine, clicked on my Glacier backup and entered my passcode in order to start the restore process.
I knew that access to Glacier files is a delayed process, but I didn’t realize that the amount you pay to restore files depends on how fast you want to download those files—something known as the “peak retrieval rate”. Naturally, I slid the bandwidth slider to the max and hit go—literally a fraction of a second before seeing the peak retrieval rate calculation appear.
So I accidentally ended up paying something like $150 to restore my data. Sigh. Onward.
Uploading to Amazon S3 with Transmit
Arq is amazingly reliable software, and so after a few hours it had successfully restored all 300 GB of my data. At that point, I was ready to move it all back into a newly-created Amazon S3 bucket. Naturally, I fired up my tried-and-true, wonderfully-intuitive file transfer software—Transmit.
Using Transmit, I connected to my S3 bucket, dragged in the 300GB of data, watched it start the upload process—and then left to go do something else, since I knew the upload would take several hours.
And several hours later, when I came back to check on everything, I found Transmit paused with an error alert waiting for my confirmation:
This file can’t be uploaded as it exceeds the maximum upload size.
Oh no. Don’t tell me there’s a maximum up-loadable file size! And if there is, why didn’t Arq run into that same problem when it did it’s original backup to S3/Glacier?
The file in question was about 8GB in size. Doing some investigation, I learned there is a maximum upload size, but it’s something like 1TB. But…to upload any file larger than 5GB, you have to use what’s called “multi-part” upload, which Transmit unfortunately doesn’t support.
After more investigation, I discovered that pretty much the only app for Mac OS X platform that supports multi-part S3 uploads is the unfortunately named, “Cyberduck”.
You paid for Cyberduck?
Glancing at the website, I immediately knew that, from a UI perspective, Cyberduck wasn’t going to be anywhere near as intuitive as Transmit. But, being the only game in town, I clicked on the App Store icon, paid my $24 and downloaded it.
Not knowing exactly how far Transmit got into the upload process, I figured it would be best to use the “synchronize” feature in Cyberduck, to compare the local folder to that in S3, and upload any missing files. And this is where I hit the first UI issues.
This is what you see when you initiate the synchronization of two folders in Transmit:
It’s easy to tell in which direction the synchronization will apply, what’s going to happen to orphaned files, what the comparison criteria will be, and you can even simulate the synchronization process first for safety.
Here’s what you see in Cyberduck:
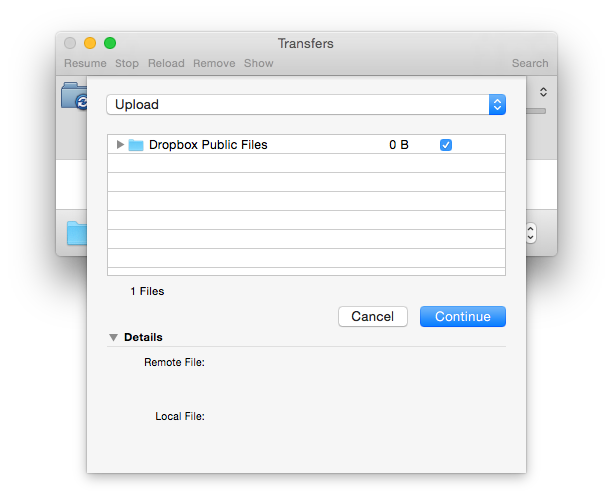
What does this mean? Am I synchronizing “1 Files” or a folder? What does “0B” of data mean—that nothing will be synced? Why are the “Details” empty? A screen like this makes you want to down a whiskey before clicking that “Continue” button.
But I did click the Continue button, and proceeded to watch Cyberduck start calculating MD5 hashes on each and every file to determine whether they need to be synced or not—a much slower process than Transmit’s simpler file-size comparison.
So again, I went away, hoping to come back later and find the whole thing done. And, of course, I knew it wouldn’t be that easy.
When I came back, I found Cyberduck alerting me:
The network connection was interrupted, would you like to try again?
Heavy sigh. Of course I do.
So it’s off to the settings, where I discover that you can enable “auto-retry” on network interruptions. (Why this isn’t enabled by default is anybody’s guess.) The setting requires that you specify a maximum number of retries before giving up, and so I set that to the maximum of nine.
Once again, I started the synchronization process and went away. Upon returning, as if living a bad dream, I found Cyberduck reporting:
The network connection was interrupted, but I will I auto-retry now. You have 8 auto-retries left. Oh, can you please confirm again you want to synchronizes these two folders? Continue.”
So it’s happy to auto-retry the interrupted network connection, but only after I re-confirm that I really want to synchronize these folders. Heavy, heavy sigh.
With that, it was time email Cyberduck for some support. They wrote back that the sync re-confirmation is a bug, and that I could go ahead and download the fix by going to the “Update” area in the settings and grabbing the latest “snapshot build”.
Great!—except that my copy of Cyberduck doesn’t have an Update area in the settings. Why? Because I bought the $24 App Store version of the program, instead of DOWNLOADING THE FREE VERSION FROM THE WEBSITE!!!
Long story short (too late, I know), I then went and downloaded the FREE version of the app (overwriting my paid App Store version), updated to the latest snapshot, ran the sync process—and 24 hours later had all my data finally uploaded to my Amazon S3 bucket.
(Actually, it wasn’t quite that easy. During the subsequent synchronization process, I discovered that the maximum auto-retry setting is cumulative over the entire synchronization process. So frequently I’d return to the computer to discovered the process quit after having been interrupted nine times, even though the auto-retry was successful after each one.
I emailed the author, and he agreed that the setting should apply to a single interruption, and should reset after each successful retry.)
It’s all in Glacier! But how do I restore it?
As mentioned earlier, I set a lifecycle rule on my S3 bucket to move all files to Glacier one day after they’ve been created. So 24 hours later, I confirmed from the Amazon AWS console that, indeed, all my files had been moved from the S3 class to the tremendously economical Glacier class of storage. Yeah!
Then I got to thinking, what if I need to restore these files?
Noticing that all my files still appeared in a Transmit (or Cyberduck) directory listing, I just tried double-clicking one to see what would happen. Transmit reported a permission error when attempting to download it.
Turns out, you have to first restore them to S3 using the Amazon AWS Console, and then they’ll be downloadable using something like Transmit. From within the console, after having selected one or more files, you’ll find a “Restore” function in the “Actions” drop-down menu. When you choose to Restore a file (or files) you’re asked how long you want them to remain available in S3, before they are reverted back into Glacier.
That seemed quite nice, but then I discovered a huge problem. What if I wanted to restore an entire folder of files?
When you select a folder, instead of a file, and click the “Actions” drop-down menu, you won’t find a “Restore” function. That’s right—you can’t restore an entire folder of files; instead, you have to actually select and restore files individually.
Can you imagine the work involved in restoring an entire, deep hierarchy of files?
A bit of Googling revealed that with some scripting, you can use S3 command-line tools to recursively crawl your Glacier hierarchy, restoring your files—something I would never try doing myself. And I did find a Java-based app called “CrossFTP” that claims to be an “intuitive GUI front-end” to the command-line tools. But having looked at the “restore” screenshot on the CrossFTP website, I got the feeling its use would be nearly as risky as programming the CLI tools myself.
So that’s where I am. Happy to have all my data hosted cheaply in Glacier. Unhappy to have spent so much money getting it there. Happy to decommission my old hard drives at home. And hoping when the day comes that I need to do a mass-restore of my data, that a decent Glacier client will have appeared on the Mac platform, or that one of the existing apps like Transmit will have evolved to support that. (I did send the Arq author an email asking if he’d be interested in developing such an app, but haven’t heard back.)
Enjoy this article? — You can find similar content via the category and tag links below.
Categories — Technology
Tags — Apple
Questions or comments? — Feel free to email me using the contact form below, or reach out on Twitter.